菜单
首页财产ai正文 字节Seed最新模子,让豆包学会闭嘴听人措辞 4月9日字节跳动旗下AI研究团队Seed发布新语音模子Seeduplex并全量上线豆包App,其全双工特征晋升语音交互体验,解决繁杂场景问题,但与真人对于话仍有差距 。 2026-04-10 16:21 ·微信公家号:硅星人董道力 AI投资人解读· 字节跳动旗下AI研究团队Seed发布新语音模子Seeduplex并全量上线,其亮点是全双工,能同时收发旌旗灯号,互不滋扰,解决了此前语音模子的问题,晋升了语音质量及交互体验,还有扩大了利用场景。 · 全双工语音AI竞争格式中,原生音频全双工虽走患上远但难落地,Thinker-Talker分散架构有价钱,流式级联管道方案无全双工能力,Seeduplex于豆包上不变运行,但与真人对于话流利度仍有差距。 总结:Seeduplex的全双工技能有上风,为语音交互带来新可能,但于不变性及对于话流利度上仍需改良,将来还有有许多工程难题待解,不外其于语音AI成长中是主要节点,具有投资潜力,值患上存眷技能迭代及运用场景拓展。内容由AI天生,仅供参考
4 月 9 日,字节跳动旗下 AI 研究团队 Seed 发布了新的语音模子 Seeduplex,同步完成为了于豆包 App 的全量上线。
语音模子咱们已经经见过许多了,更新迭代无非是声音更拟人、延迟更低。而 Seeduplex 的亮点不于这些,而是它文章标题里藏着的一个词:Full-Duplex,中文翻译过来叫“全双工”。
这几个字,到底甚么意思。
豆包学会边说边听
全双工是通讯工程里的术语,简朴来讲,就是通讯两边可以同时收发旌旗灯号,互不滋扰。
好比对于讲机是半双工,统一时刻只能一小我私家措辞,说完松开按钮对于刚刚能启齿,而德律风是全双工,两小我私家可以同时措辞,同时听。
豆包此前的语音模子,素质上是对于讲机逻辑。架构上"听"及"说"是两个自力状况,不克不及同时运行。
模子于输出语音的时辰,麦克风输入要末被关失,要末不被处置惩罚。判定你是否说完了的,是一个叫 VAD(语音勾当检测)的自力模块,检测到声音停了,才切换到"处置惩罚"状况,再天生答复。
VAD 只看声音有无,不懂你于说甚么。你停两秒想词,它判断你说完了,阁下有人咳嗽,它判断你启齿了。
按字节的技能文档说法,传统半双工体系"利用自力的 VAD 举行机械式音频支解,因为决议计划仅限在伶仃的声学特性或者局部文本语义特性,这些体系于繁杂情况中轻易被带跑,或者于用户搁浅时触发过早相应"。
Seeduplex 则解决了这个问题。
模子于措辞的同时,连续处置惩罚麦克风输入,及时判定哪些声音是用户于对于它措辞,哪些是配景噪音,哪些是搁浅思索而不是说完了。
这套判定交由统一个 LLM 同一完成,声学特性及语义上下文同时介入决议计划,再也不是几个自力模块各干各的。及此前豆包利用的半双工框架比拟,Seeduplex 的判停 MOS 分提高了 8%,对于话流利度 MOS 分晋升了 12%。
(MOS 是通讯范畴权衡语音质量的主不雅评测尺度,素质上是让真实用户打分,再取平均值。分数越高,代表用户感知到的体验越好。)
详细指标上,判停延迟降低约 250ms,繁杂场景下 AI 抢话比例削减 40%,用户想打断时,相应延迟缩短约 300ms,正确率同步晋升,繁杂声学滋扰场景下,误答复率及误打断率降低一半。
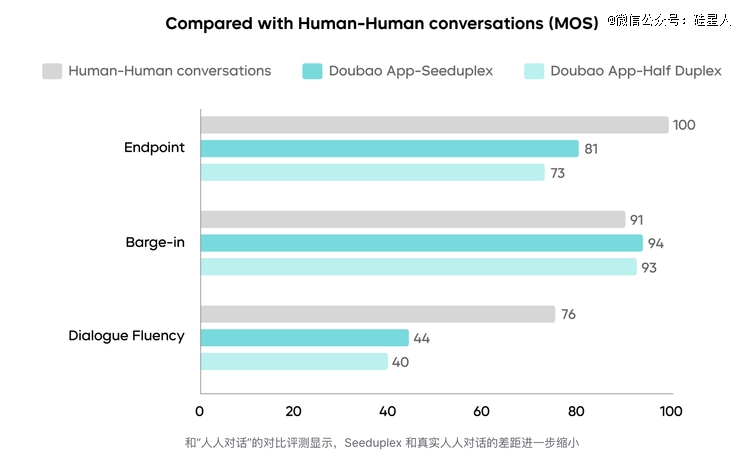
字节还有做了一组真人对于话测试,把 Seeduplex、半双工方案及人人对于话放于一路比。判停上 Seeduplex 比半双工晋升了 8%。相应打断上甚至略好过人人对于话的平均程度,由于真实对于话里人也会偶然反映慢(实在半双工也好过人人)。但总体对于话流利度上,及真人谈天仍有不小的差距。
全双工的豆包交互越发天然
说完技能层面的变化,利用场景上,全双工的 AI 语音的界限也有不小扩大。
好比开车时,车里播送及导航同时于响,你顺口问 AI"这条路堵不堵",Seeduplex 能从稠浊的声音里分辩出哪句是你说的,直接回覆,而不是被导航播报带跑。
于咖啡馆遇到伴侣打了个号召,或者者快递员敲门你随口应了一声,AI 能判定出这些话不是对于它说的,不会插进来乱回。
练英语白话时,你磕磕绊绊说了半句,停下来想词,改口重说,AI 不会于你搁浅的间隙抢话,而是等你把完备的意思说出来,再给反馈。
这几个场景有一个配合点:你不需要专门腾出时间、找平静处所、说完备句子。对于话嵌进了一样平常勾当,而不是一样平常勾当为对于话让路。
全双工还有带来了一种新的交互可能,AI 最先有了"措辞间隙"。之前 AI 措辞时你只能等,或者者作声强行打断,但它停下来不是由于听懂了你想说甚么,而是检测到有声音进来了。此刻你说"等一下",它能听懂这是打断用意,马上停下来。
反过来,当你于措辞时,AI 也能给出及时的回应旌旗灯号,好比"嗯""好的",而不是缄默沉静着等你把话说完。
这类你来我往的节拍,是半双工架构物理上做不到的事。
以前的半双工 AI 语音的隐性条件是,用户必需进入"利用 AI 模式"。这个条件把语音 AI 的可用处景锁于了一个很窄的规模里。
全双工解决了这个条件,让用户更愿意及豆包对于话了。
AI 语音助手的技能分野
全双工语音 AI 的竞争格式,今朝有几个标的目的于跑,技能线路差异很年夜。
原生音频全双工是走患上最远、也最难落地的一条。
代表是法国 AI 试验室 Kyutai 于 2024 年 9 月发布的开源模子 Moshi,用统一个底层模子于并行流上同时对于用户音频及体系音频建模,并引入"心田独白"机制,于天生音频的同时猜测对于齐文本作为内部推理层,顺带得到了流式转写能力。
NVIDIA 本年 1 月发布的 PersonaPlex 于此基础上引入混淆提醒体系,让模子可以经由过程文字界说脚色、语音嵌入界说声音特性,饰演特定人格。
这个标的目的的问题是不变性,学术前驱占多数,没有产物化落地。

Thinker-Talker分散架构是另外一种实现路径。
阿里 2025 年 3 月发布的 Qwen2.5-Omni 将推理及输出拆成 Thinker 与 Talker 两个组件,前者于文本域完成推理,后者把成果及时转为音频,LLM 生态的长上下文、东西挪用、检索注入全数可以复用。
价钱是同时据说比双流方案更难实现,端到端延迟高在流式级联管道方案。
流式级联管道(ASR→LLM→TTS)是今朝出产情况最遍及的方案。延迟可控于 1 秒之内,东西挪用撑持最成熟,但素质是轮流制,体系必需等用户说完才能处置惩罚,全双工能力无从谈起。
Seeduplex 属在原生音频全双工标的目的,但解决了其他方案没有解决的问题:于豆包上不变运行。
学术情况及产物情况的差距,比大都人想象的年夜。字节于技能文档中提到,落地历程中需要解决的包括高并发下的延迟抖动、音频输入输出卡顿及办事不变性,这些问题于论文里不存于,于数亿用户眼前全会呈现。
全双工解决了能不克不及同时据说的问题,说患上多天然还有需要改良。
字节本身于文章末尾也认可,与真人对于话比拟,总体流利度仍有相称差距。下一步包括多方对于话场景优化、引入视觉输入实现听看说联动,以和边听边思索、边听边搜刮等标的目的,每个都是新的工程难题。
从对于讲机到德律风,中间有许多年的演化,Seeduplex 是这条路上的一个节点,不是尽头。
【本文由投资界互助伙伴微信公家号:硅星人授权发布,本平台仅提供信息存储办事。】若有任何疑难,请接洽(editor@zero2ipo.com.cn)投资界处置惩罚。
-南宫娱乐相信品牌的力量