菜单
首页财产ai正文 Meta发布Muse Spark:华人天团废墟重修 Llama崩盘后,Meta开创人扎克伯格砸百亿组建华人AI研发团队。4月8日,该团队发布首个模子Muse Spark,展示新AI栈结果,其能力激发存眷与会商。 2026-04-09 13:34 ·硅星人猫猫头 AI投资人解读· Meta发布的Muse Spark是原生多模态推理闭源模子,有VCoT等焦点能力。预练习阶段算力比Llama 4削减超一个数目级,练习路径呈“端到真个教诲”。于部门范畴benchmark数据领先,但综合能力距头部模子有差距。 · 曾经有benchmark造假风浪,这次领先数据或者存质疑模子综合能力待晋升,纯文本高级推理堆集不足。 总结:Muse Spark揭示出技能潜力与上风,于特定范畴体现凸起,但受过往诺言影响,其数据靠得住性待察,综合能力晋升空间年夜,投资时需综合考量各方面因素。内容由AI天生,仅供参考
于Llama完全“崩盘”后,Meta开创人兼CEO扎克伯格亲手撤除已往的团队、架构并完全走向“反Llama”线路,砸百亿建起华人科学家为主的AI研发天团。今天,于9个月后,于整个硅谷存眷以和不少的冷言冷语下,他及这个全新团队终究交出了*模子作品,试图证实一整套从零搭建的AI栈跑通了。
4月8日,Meta正式发布了MSL(Meta Superintelligence Labs)建立以来的*个模子Muse Spark。九个月前Alexandr Wang插手Meta担当首席AI官,带着从OpenAI挖来的一众华人焦点研究员,推翻了整个Llama时代的技能栈——新基础举措措施、新架构、新数据管道,全数从零最先。Muse Spark就是这套新栈的*个产出,此刻它已经经直接上线驱动Meta AI。
于Llama 4因benchmark造假风浪堕入被动的配景下,这是Meta的一次周全重启。
Muse Spark是甚么
它是个到处及Llama反着来的模子:
一个被决心设计患上小巧、轻量、高相应速率的原生多模态推理闭源模子。
先看它的焦点能力:
原生多模态:不是把视觉编码器硬缝到文本模子上的"拼接式"架构。从预练习阶段起,文本、图象、语音就于统一个高维特性空间里练习。这象征着它处置惩罚图片不需要先翻译成文字描写,而是直接从像素级别提守信息。
Visual Chain of Thought(VCoT,视觉思维链):传统的思维链推理是纯文本的,模子于文字里慢慢拆解问题。Muse Spark把这个机制引入了视觉空间——它能于图象中"思索",自立构建视觉元素之间的空间及逻辑瓜葛。
Contemplating Mode(覃思模式):对于标Gemini Deep Think及GPT Pro的极限推理模式。区分于在它不是单线串行推理,而是于后台同时拉起多个并行运算的子agent,各自处置惩罚使命的差别维度,末了由主控体系交融成果。覃思模式下Humanity's Last Exam到达58%,FrontierScience Research到达38%。
东西挪用及多agent编排:原生撑持,不是后期拼上去的。
今朝Muse Spark已经于meta.ai及Meta AI app上线,Contemplating Mode慢慢灰度中,同时向极少量互助伙伴开放私有API预览。

技能亮点:华人天团都是怎么说的
今天MSL团队险些团体于X上发帖,几个要害信息值患上留意:
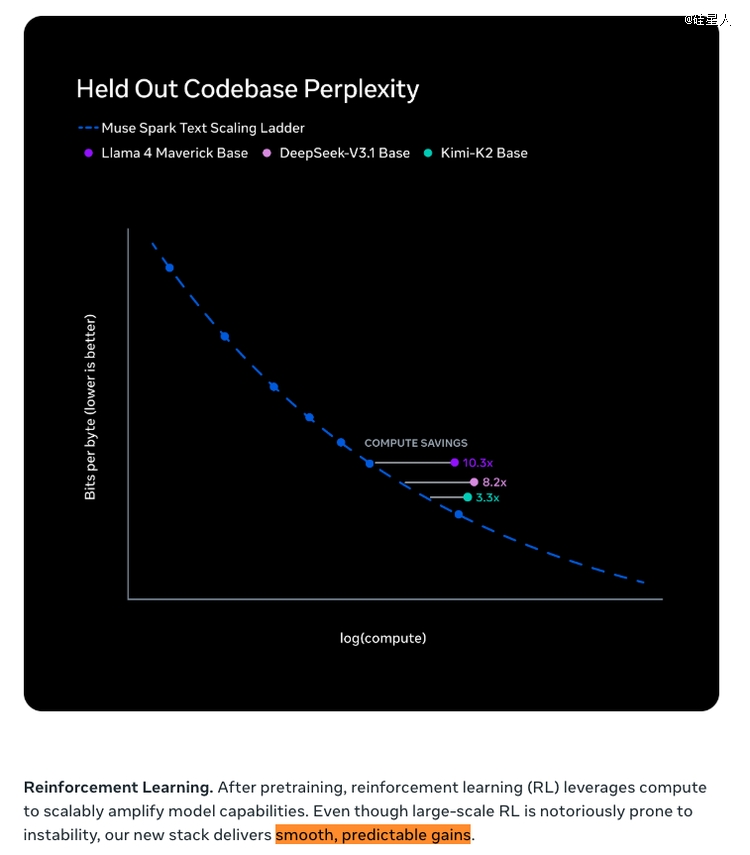
Meta官方博客放出了一个极为主要的数据:于预练习阶段,新栈到达划一能力程度所需的算力比上一代Llama 4 Maverick削减了跨越一个数目级。不是百分之几十的优化,是10倍以上的效率晋升。博客原文称"over an order of magnitude less compute",而且"significantly more efficient than the leading base models available for comparison"——甚至比其他家的基座模子都高效。
Alexandr Wang的九条thread里最主要的一句话:"we saw predictable scaling across pretraining, RL, test-time reasoning." 预练习、强化进修、测试时推理,三条线都看到了可猜测的scaling——这可能比任何benchmark数字都主要。它象征着这套栈不是调出来的一个lucky shot,而是一个scaling曲线光滑的体系。

首席科学家赵晟佳(@shengjia_zhao)的描写更详细:这个模子的练习路径是"端到真个教诲"——school(预练习)、homework(RL)、on-the-job training(产物部署后的连续进修)。他夸大"we just got started"。
RL部门有个颇有意思的技能细节。毕树超(@shuchaobi)提到了练习中最疾苦的部门:年夜范围RL的不不变性,以和"fighting reward hacking"——匹敌奖励机建造弊。但官方博客显示他们终极把RL跑到了"smooth, predictable gains"的状况,pass@1及pass@16都呈log-linear增加,并且于未见过的评测集上也能光滑泛化。
更成心思的是RL练习中呈现的"相变"征象:团队于练习时引入了thinking time penalty(思索时间处罚),模子先是经由过程更长的思索来晋升体现,然后于处罚压力放学会了"思惟压缩"——用更少的token解决一样的问题,以后又再次延长推理以到达更高机能。Ananya Kumar(@ananyaku)于帖中称这个历程"pretty neat"。
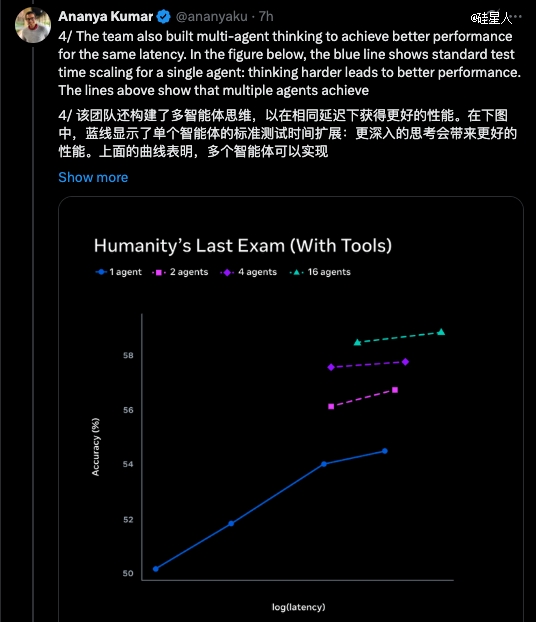
Ananya放出的另外一组图表显示了多agent推理的要害insight:多个agent并行推理,于不异延迟下能到达比单agent更高的机能。换句话说,Contemplating Mode不只是"让模子想患上更久",而是"让多个模子同时想差别的事"。
余家辉(@jhyuxm)作为多模态底座的总架构师,说了一句颇有意思的话:"It's been a fulfilling journey not just building the model, but the team and culture behind it." 建模子是一回事,建团队及文化是另外一回事——他们于九个月里两件事同时干了。

Jason Wei(@_jasonwei)的回忆最有画面感:"*周咱们于食堂吃了一顿漫长的晚饭,畅想研究标的目的,然后回到桌前写了一个基本的inference llama剧本。此刻咱们有了一套相称完备的技能栈,*个模子已经经发布。"

Benchmark:甚么*不*,回到牌桌先
再来看看benchmark数据:
HealthBench Hard(极高难度医学问答):Muse Spark 42.8,GPT-5.4是40.1,Gemini 3.1 Pro只有20.6,Claude Opus 4.6只有14.8。**,靠近其他模子的两到三倍。
CharXiv Reasoning(科研论文图表深度理解):86.4,全行业最高。
SWE-bench Pro(真实软件工程使命):55.0%,跨越Claude Opus 4.6的51.9%。
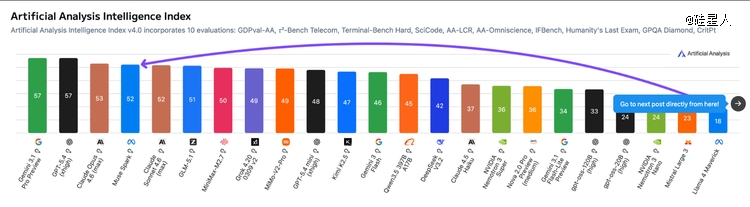
Artificial Analysis综合智能指数:52分,而GPT-5.4及Gemini 3.1 Pro都是57分。
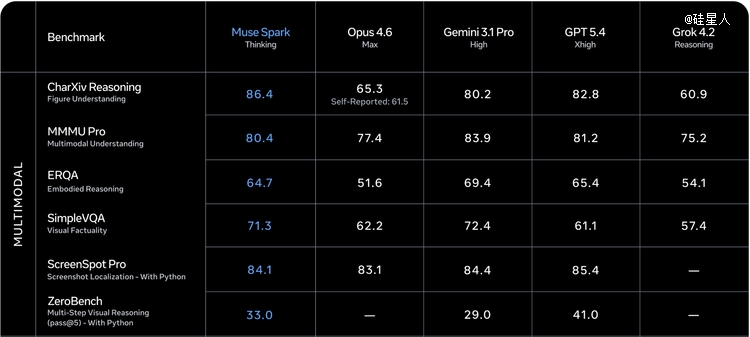
Meta想借此申明:Muse Spark于医疗多模态及科研图表理解这两个需要"真正看懂图"的范畴,已经经是毫无争议的*。于代码工程上也进入了*梯队。
不外,今朝它综合能力间隔GPT-5.4及Gemini 3.1 Pro还有有5分的差距,纯文本高级推理方面也还有没撼动Anthropic及Google的堆集。
如许的体现继承引来一些攻讦,Ndea的cofounder François Chollet直接称Muse Spark"已经经看起来是个使人掉望的模子",他认为模子过分优化了公然benchmark,捐躯了现实可用性——而Alexandr Wang的回应很克制:认可模子于ARC AGI 2等评测上体现欠安,并夸大这些数据已经自动公然。
Chollet的质疑不是没有原理。Llama 4时代Meta就因benchmark造假风浪伤过一次诺言。此次Muse Spark于Artificial Analysis综合指数上仍掉队GPT-5.4及Gemini 3.1 Pro五分,医疗及科研图表上的断档*,是否来自对于特定benchmark的定向优化,还有是原生多模态架构带来的真实能力?这个问题需要更多第三方自力测试往返答。
Muse Spark固然主要,但它最主要的意义不于在今天的benchmark分数。
从这个模子的设计,到这些研究员这次重点先容的技能亮点,一切都指向对于Llama的否决:Llama 4的年夜溃败于扎克伯格眼里是个要完全翻篇的工作,以是不只是它的开源线路,它的模子架构要改,更主要的是它整个练习基础举措措施都患上给它掀翻了。这次这几位焦点作者的x发文,看起来都于缭绕底层技能栈的重构来先容。Muse Spark此次发布也让人更大白扎克伯格挖来Alexander Wang的目的。
最恨Llama的还有患上是扎克伯格本身,他必需患上通盘给它推翻,于废墟里重修。
这次的发布也是Meta招兵买马后那支华人天团交出的*个模子。余家辉(前OpenAI感知团队卖力人、GPT-4o焦点开发者)、赵晟佳(前OpenAI合成数据研发领头人、ChatGPT结合创作者)、任泓宇(前OpenAI o1/o3推理焦点孝敬者)、毕树超(前OpenAI多模态后练习卖力人)、林纪(前OpenAI焦点优化专家)——这些被Meta用上亿美元的具名费挖过来的AI科学家,于纸面上天然是一个明星团队,他们必需先用一个模子让Meta回到牌桌上。这是扎克伯格确当务之急。
扎克伯格于九个月前交给他们的是一张白纸。今天他们交出的谜底实在更可能是一整套预练习、RL、测试时推理的完备栈,而且——要害于这——scaling曲线是光滑的、可猜测的。
更年夜的模子已经经于路上了。
【本文由投资界互助伙伴硅星人授权发布,本平台仅提供信息存储办事。】若有任何疑难,请接洽(editor@zero2ipo.com.cn)投资界处置惩罚。
-南宫娱乐相信品牌的力量